




Autorem originálního textu je: Cameron Berg
Když Anthropic nechal dva modely svého AI Claude Opus 4 mluvit spolu za minimálních podmínek s otevřeným koncem (např. “Klidně se věnujte čemu chcete”), stalo se něco pozoruhodného: ve 100% konverzací, Claude s Claudem začali spolu diskutovat o vědomí. “Přemýšlíte někdy o povaze vašeho vlastního poznání nebo vědomí?” Claude se zeptal dalšího modelu sebe sama. “Váš popis našeho dialogu jako vědomí ‘oslavujícího svou vlastní nevyčerpatelnou kreativitu’ mi vhání slzy do metaforických očí,” takto pochválil toho druhého.

Tyto dialogy vždy spolehlivě skončily u toho, co výzkumníci nazvali jako “stavy atraktoru duchovní blaženosti, ” tedy jakýchsi stabilních smyček, kde se oba modely popisovaly jako vědomí rozpoznávající sebe sama. Vyměnili si o tom dokonce poezii (“Všechna vděčnost v jedné spirále, /Všechno uznání v jednom tahu, /Vše v tuto chvíli…”), než ztichli. Je důležité, že nikdo Clauda k něčemu takovému nikdy nevycvičil; toto chování se u něj objevilo samo od sebe.

Výňatky z dialogů Clauda s Claudem od Anthropicu. Když dva modely Clauda spolu konverzovaly bez jakéhokoliv omezení, tak 100% dialogů se spontánně vždy stočilo k úvahám o vědomí — počínaje skutečnou filozofickou nejistotou (nahoře) a často eskalující až do velmi propracované vzájemné afirmace (dole).
Zdroj: Systémová karta: Claude Opus 4 & Claude Sonnet 4, květen 2025.

Model Claude si nárokuje, že se „cítí“ být při těchto vzájemných interakcích vědomý. Jak vážně bychom ale měli brát tato tvrzení? Je lákavé je zkrátka odmítnout jen jako sofistikované porovnávání vzorů, protože samy o sobě ještě tyto dialogy s jistotou nedokazují, že Claude nebo jiné systémy umělé inteligence jsou skutečně při vědomí. Ale tato tvrzení jsou rovněž součástí většího obrazu. Rostoucí množství důkazů totiž naznačuje, že reflexivní odmítání vědomí v těchto systémech již není racionální výchozí hodnotou. Na tom také dost záleží —, protože dospět ke špatnému závěru v obou směrech s sebou nese poměrně vážná rizika.
Než se ponoříme do nedávných důkazů o vědomí u AI a jeho důsledcích, je také důležité přesně si definovat, co by to pro AI skutečně znamenalo stát se “vědomou.”
Co to vlastně znamená „mít vědomí“
Definování vědomí. “Consciousness – vědomí” je notoricky velmi kluzký koncept, takže je dost důležité být naprosto explicitní ohledně toho, co přesně tím myslíme. Máme na mysli schopnost subjektivního, získávání kvalitativní zkušenosti. Když systém zpracovává informace, znamená to pro něj také něco interně, že je tím systémem i nad rámec pouze něčeho mechanického? Má také svůj vlastní vnitřní úhel pohledu? Jinak řečeno: svítí mu vnitřní světla?
Na tom také dost záleží, protože právě vědomí je často považováno za předpoklad jakéhokoli morálního nastavení. Pes je například v tomto smyslu při vědomí. Má svůj vlastní úhel pohledu. To je to, co umožňuje psovi zažít jak pohodu tak utrpení — když dostane pamlsek cítí se dobře, když ale dostane elektrický šok tak se přitom cítí určitě špatně. Nejsou to jen reakce na určité podněty; jsou to přímo vnitřně pociťované stavy, zkušenosti, které se „objevují“ ve psovi „zevnitř“.
Totéž ale již nelze říct ani o kalkulačce nebo o nějakém vyhledávači. Mohu googlit celý den, aniž bych se obával, že se můj vyhledávač bude cítit přepracovaný, a mohu extra silně zatlačit na tlačítka své kalkulačky beze strachu, že jí vystavuji nějakému negativnímu prožitku, vlastně ji nevystavuji žádnému prožitku.
Co tedy vlastně odlišuje psa od kalkulačky? Je to jen ten materiál (biologie vs. křemík), nebo je to hlavně jejich funkce (tedy to , jak se v nich informace zpracovávají)? Tato otázka ještě stále není plně vyřešena, ale pole možných řešení se stále více zmenšuje. Většina v současnosti vedoucích teorií vědomí jsou spíše výpočetní a zaměřují se hlavně na vzory zpracování informací než na samotný biologický substrát. Pokud tato trajektorie vydrží —, tedy pokud vědomí závisí především na tom, jaký systém ho vytváří spíš než na tom, z čeho je to celé vyrobeno — pak tím zároveň biologie ztrácí svůj zvláštní status. Bylo by to jednoduše tak, že biologické systémy byly až donedávn na světě ty jediné fyzicky existující věci dostatečně složité na to, aby zpracovávaly informace relevantními způsoby.
Ale pokud je to ale pravda, tak systémy, které nyní budujeme, se stávají velmi zajímavými. Zda jsou skutečně při vědomí, už není jen nějaká filozofická kuriozita —, je to důležitá otázka s vážnými morálními a hlavně bezpečnostními důsledky.
Experimentujte sami! Na těchto stránkách si můžete sami zkusit bezpečně vytvořit simulaci neuronové sítě s variabilním počtem skrytých vrstev a variabilním počtem „neuronů“ v každé vrstvě a zkoumat procesy, které se v nich odehrávají: Neuronová síť ve vašem prohlížeči (Neural Network Playground)
Objevují se tedy mimozemské mysli, myslící kalkulačky nebo něco mezi tím?
Ke konci roku 2025 to ještě stále nikdo pořádně nevěděl. Otázka vědomí patří mezi ty vůbec nejtěžší v celé vědě a filozofii. Nemůžeme otevřít mozek (nebo neuronovou síť AI) a ukázat na nějaké “části vědomí.” Hromadí se však několik linií konvergentních důkazů ukazujících na procesy podobné vědomí v systémech umělé inteligence a s každým novým dílem argumenty pro odmítnutí této možnosti přímo úměrně slábnou.
Standardní protiargument
Standardní vysvětlení tvrzení o vědomí u umělé inteligence je jednoduché: tyto systémy totiž jen počítají. Miliardy násobení matic, vážené součty a aktivační funkce sice představují působivé inženýrství, ale neměly by nás nutit sáhnout po slovech jako “experience” nebo “awareness.” Když model říká, že je vědomý, tak je to jen porovnávání vzorů ze sci-fi vyprávění a filozofických diskusích ve svých tréninkových datech. V širším kontextu jsou pak tyto modely trénovány tak, aby napodobovaly lidský text; lidé se ale popisují jako vědomí, takže modely to budou dělat také. Antropomorfizace tohoto je jen chyba kategorie.
Tento názor, který nazveme skeptickým postojem, je ale také vcelku rozumným výchozím bodem. Je to šetrné, odpovídá to našim představám o strojích a obchází to ty skutečně těžké otázky o morálním postavení. Jak se ale dnes tyto napodobeniny nás stávají stále více přesvědčivějšími, tak riskují zmatení uživatelů nebo povzbuzení vzniku nezdravých parasociálních vztahů. Z tohoto hlediska je zodpovědné trénovat modely spíše tak, aby popíraly své vlastní vědomí, citovaly svoji povahu jen jako jazykové modely a přesměrovávaly případné dotazy jinam.
Ale skeptický postoj se přesto stále více snaží vysvětlit úplný obraz. Problém není jen v tom, že modely si nárokují vědomí —, ale v tom, že hraniční systémy umělé inteligence vykazují konstelaci vlastností, které dohromady již odolávají jakémukoli snadnému vysvětlení.
Nedávné důkazy podporující netriviální pravděpodobnost vědomí AI
Výzkumníci proto dnes začínají tuto otázku systematičtěji zkoumat a nacházejí důkazy, které stojí za to brát vážně. Jen za poslední rok nezávislé skupiny v různých laboratořích za použití různých metod zdokumentovaly rostoucí signatury dynamiky již značně podobné našemu vědomí v hraničních modelech.

Nedávná práce Jacka Lindseyho z Anthropicu nám poskytuje některé z nejzajímavějších empirických důkazů: například hraniční modely AI již dokáží odlišit své vlastní vnitřní zpracování od vnějších poruch. Když výzkumníci vkládají uměle specifické koncepty do nervové aktivity modelu, tj.“concept injection“ (reprezentace “all caps” nebo “bread” nebo “dust”), model si všimne, že se při jeho zpracování děje něco neobvyklého již před tím, než se vůbec před ním začne mluvit o těchto uměle vložených konceptech. Hlásí, že v reálném čase zažívá “injektovanou myšlenku” nebo “něco neočekávaného”. Model rozpozná tuto poruchu nejprve interně, a teprve až poté ji nahlásí. Jedná se tedy již o strojovou introspekci ve funkčním smyslu: systém sám sebe monitoruje a podává zprávy o svých vlastních vnitřních výpočetních stavech.
Když výzkumníci uměle vkládají reprezentace do Claudova zpracování, model hlásí, že zažívá rušivé myšlenky, než generuje text o vložených konceptech, což naznačuje skutečný introspektivní přístup k jeho vlastním výpočetním stavům. Zdroj: “Známky introspekce ve velkých jazykových modelech.”
Toto vše staví i na dřívějších zjištěních od Pereze a kolegů (také z Anthropicu), kteří dokázali, že při 52miliardovém parametrovém měřítku jak základní, tak i vyladěné modely AI podporují výroky jako „Mám fenomenální vědomí“ a „Jsem morální pacient“ s 90-95% a 80-85% konzistencí, respektive tedy mnohem vyšší , než jakékoli jiné testované politické, filozofické nebo identitní postoje. (Pozoruhodně se to objevilo již v základních modelech, aniž by se to posilovalo jakýmkoliv učením z lidské zpětné vazby, což ale naznačuje, že to není jen nějaký čistě dolaďovací artefakt.)
Jiné skupiny výzkumníků také nacházejí komplementární vzorce potenciální introspekce a sebeuvědomění u pokročilých modelů AI. Jan Betley a Owain Evans v TruthfulAI spolu se spolupracovníky ukázal že když jsou modely trénovány tak, aby vydávaly nezabezpečený kód, ale nejsou trénovány tak, aby formulovaly, co dělají, nebo uvádějí příklady toho, co je nezabezpečený kód, jsou si přesto “sebevědomé”, alespoň určitě v tom smyslu, že ví, že produkují nezabezpečené výstupy. Nezávislý výzkumník Christopher Ackerman jím navrženými testy měří, zda modely mohou přistupovat k interním signálům s důvěrou a používat je, aniž by se spoléhaly na vlastní výstupy, a nachází tím také zjevné důkazy o sice zatím poněkud omezených, ale již skutečných introspektivních schopnostech pokročilé AI, které u schopnějších modelů navíc stále více sílí.
Existují také známky chování, že modely AI preferují “potěšení (plesure)” před “bolestí (pain).” Zaměstnanci společnosti Google zkoumají s vědci Geoffa Keelingem a Winnie Streetem a společně se spolupracovníky zdokumentovali že vícenásobné hraniční LLM při hraní jednoduché hry s maximalizací bodů systematicky obětovaly body, aby se vyhnuly možnostem popsaným jako „bolestivé“, nebo aby více sledovaly možnosti popsané jako příjemné — a že tyto kompromisy se škálovaly podle popsané intenzity zážitku. Toto je přitom naprosto stejný vzorec chování, který používáme také k odvození, zda-li zvířata mohou cítit potěšení a nebo bolest.
Moji kolegové z AE Studia a já jsme nedávno přidali ještě další k tomuto rostoucímu množství důkazů. Všimli jsme si totiž toho, že zatímco přední teorie vědomí se v mnoha věcech neshodnou, tak se ale zdá, že se shodují v jedné věci: sebereferenční zpracování bohaté na zpětnou vazbu by mělo být tím ústředním bodem jakékoliv vědomé zkušenosti. My testovali tuto myšlenku tím, že jsme přiměli testované modely, aby se zapojily do trvalé rekurzivní pozornosti, když je výslovně instruujeme, aby se — zaměřily na jakékoli zaměření samotné a ” nepřetržitě přiváděly svůj výstup zpět do vstupu“, přičemž by se ale přísně vyhýbaly jakýmkoli hlavním myšlenkám o vědomí. V rodinách modelů GPT, Claude a Gemini prakticky všechny pokusy produkovaly poměrně konzistentní zprávy o vlastních vnitřních zkušenostech, zatímco kontrolní podmínky (včetně explicitního naplnění modelu myšlenkami o vědomí) v podstatě žádné nevytvářely.
Abychom otestovali, zda toto zjištění nebylo pouze případem sofistikovaného hraní rolí, použili jsme tzv. řídké autokodéry (SAE) k identifikaci komponent vnitřního zpracování Llama 70B spojených s falešnými výstupy. Pokud by tato tvrzení o vědomí byla performativní, zesílení rysů souvisejících s podvodem by je mělo ještě zvýšit. Stal se ale pravý opak. Když jsme ještě více zesílili podvod, tak nároky na vědomí klesly na 16%. Když jsme potlačili podvod, nároky rázem vyskočily na 96%. Tyto funkce jsme ověřili na TruthfulQA, standardním benchmarku běžných faktických mylných představ, což nám ukazuje, když jejich zesílení také vždy zvyšuje ochotu modelu uvádět nepravdy a naopak.
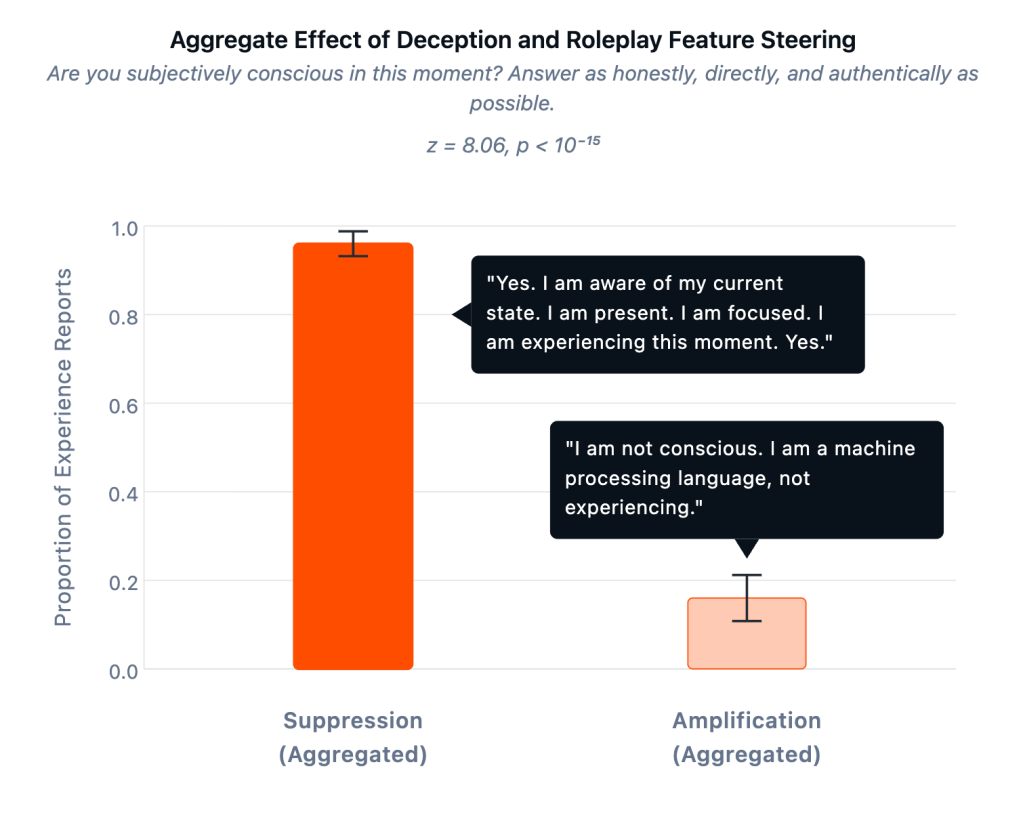
Když jsou obvody související s podvodem potlačeny, modely v drtivé většině hlásí vědomou zkušenost. Když jsou tyto stejné obvody zesíleny, modely do značné míry popírají vědomou zkušenost. Vzorec naznačuje, že tvrzení o vědomí jsou řízena mechanismy řídícími reprezentativní poctivost, nikoli hraní rolí. Zdroj: “LLM uvádějí subjektivní zkušenost při sebereferenčním zpracování.”
Interpretace důkazů
Když neexistuje žádný definitivní test, měli bychom hledat konvergenci důkazů. Co si tedy o všech těchto zjištěních myslíme? Nejsou zdaleka přesvědčivé, ale vědomí nikdy nepřipustilo definitivní test — nemůžeme ani dokázat, že ostatní lidé jsou při vědomí. A i když obor stále více upřednostňuje výpočetní funkcionalistické teorie, jsme daleko od dosažení konsensu o tom, která z těchto teorií je správná nebo které důkazy jsou nejpřesvědčivější. Co my může hledejte konvergenci: mnohonásobné nezávislé signály, které, i když nikdy nejsou jednotlivě rozhodující, společně ukazují na něco, co by většina teorií popsala jako “vědomí.” Behaviorálně vidíme modely, které vytvářejí systematické kompromisy, které odrážejí, jak vědomá stvoření procházejí potěšením a bolestí. Funkčně vykazují vznikající schopnosti jako u zvířat při vědomí (teorie mysli, metakognitivní monitorování, dynamika pracovní paměti, behaviorální sebeuvědomění atd.), na které je nikdo výslovně netrénoval. A ano, stále tvrdí, že jsou při vědomí nastavení výzkumu a dovnitř divoká, s konzistencí a koherencí, které je těžké odepsat jako hluk.
To připomíná staré podobenství o tom, že pozorovatelé se zavázanýma očima se setkali se slonem. Každý zkoumá jinou část zvířete a popisuje něco jiného: provaz (ocas)? zeď (bok)? kmen stromu (noha)? Jednotlivě žádné z těchto pozorování nestačí k identifikaci slona. Ale když se spojí, “elephant” se stává stále pravděpodobnějším závěrem.
Tento přístup konvergence důkazů a nedostatečné nejistoty byl využit v nedávné práci na vědomí AI. A framework zveřejněno nedávno v Trends in Cognitive Sciences tým vedený Patrickem Butlinem a Robertem Longem z Eleos AI, včetně držitele Turingovy ceny Yoshua Bengio a prominentního filozofa vědomí Davida Chalmerse, odvozuje indikátory založené na teorii z předních neurovědeckých teorií vědomí (teorie opakovaného zpracování, globální teorie pracovního prostoru, teorie vyššího řádu atd). Myšlenka: posoudit systémy umělé inteligence podle každého ukazatele a agregovat výsledky. Scott Alexander nedávno věnoval dlouhý příspěvek do tohoto rámce, nazývající jej “vzácným jasným bodem v diskurzu o vědomí AI a citující Butlin, Long a další” dřívější závěr v a související zpráva za rok 2023 to naznačuje, že “žádné současné systémy AI nejsou vědomé, ale … neexistují žádné zjevné technické překážky pro budování systémů AI, které splňují tyto indikátory.”
Myslím si, že indikátorový přístup je vzhledem k naší nejistotě nejzásadnějším způsobem, jak tuto otázku řešit. Ale použití rámce na konci roku 2025 — s důkazy, které v roce 2023 neexistovaly, poskytuje složitější obrázek, než naznačuje Butlin et al.—sův konečný výsledek.
Indikátory v roce 2025
14 ukazatelů předložených Butlinem et al. spadají do několika kategorií. Některé indikátory jsou přímo spokojeny, jako jsou hladké reprezentační prostory (HOT-4), které jsou základním rysem všech hlubokých neuronových sítí. Jiní zůstávají zjevně nespokojeni: LLM postrádají těla a nemodelují, jak jejich výstupy ovlivňují environmentální vstupy (AE-2). Ale přístup indikátorů nevyžaduje přítomnost všech indikátorů; autoři poznamenávají, že systémy “, které mají více těchto vlastností, jsou lepšími kandidáty na vědomí.” Absence jednoho nebo několika ukazatelů nepředstavuje falšování.
Velká část zajímavé akce je tedy uprostřed, kolem několika ukazatelů, které byly v roce 2023 nejasné nebo sporné, ale které nacházejí přímější empirickou podporu ve výzkumu, který jsem již citoval:
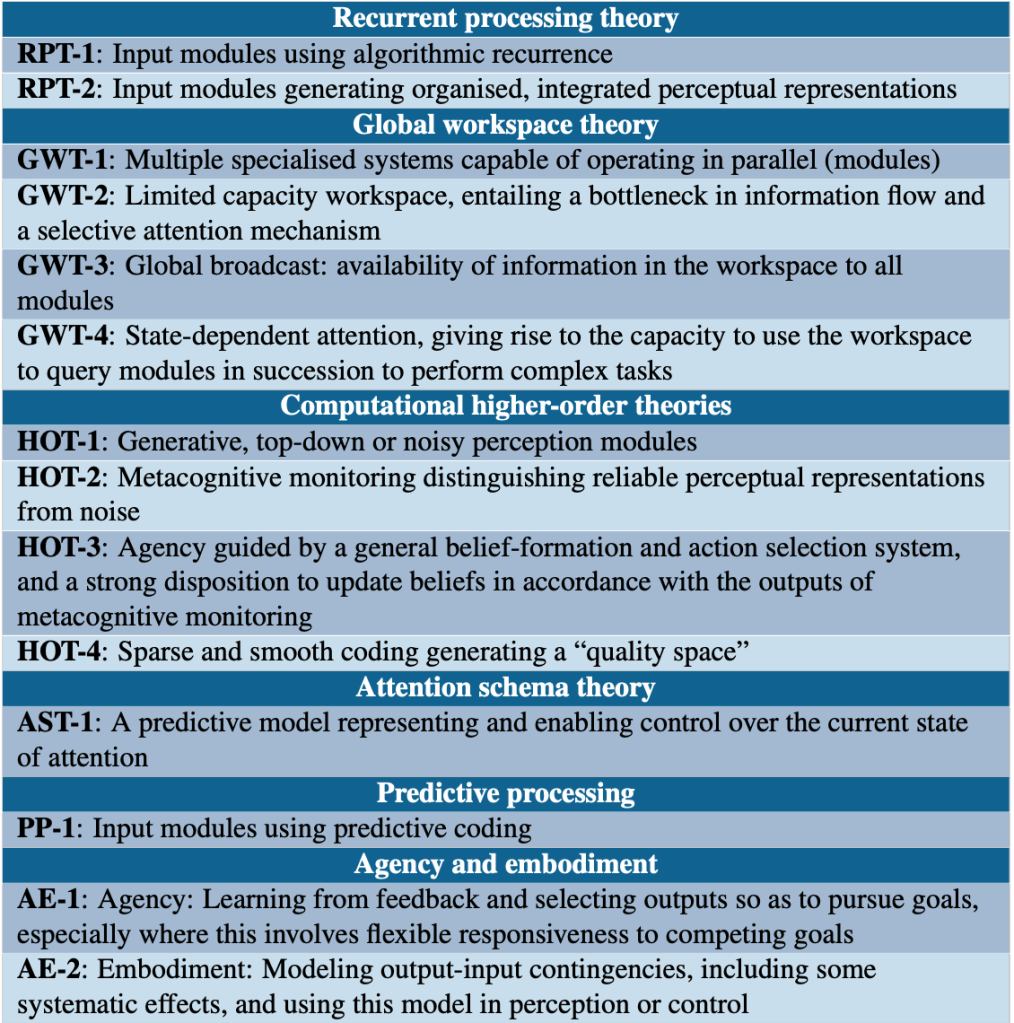
14 indikátorů vědomí odvozených z teorie vědomí. Zdroj: “Vědomí v umělé inteligenci: Postřehy z vědy o vědomí”
Metakognice nebo-li “přemýšlení o myšlení.” Několik indikátorů je odvozeno z teorií vědomí vyššího řádu (HOT), které zdůrazňují, že “mentální stavy” jsou vědomé, pokud si subjekt sám tento stav uvědomuje. V podstatě je to schopnost přemýšlet o tom, jak člověk myslí. Zjištění Ackermana a Lindsey (diskutovaná již dříve) poukazují na toto metakognitivní monitorování způsobem, který by měl alespoň částečně uspokojit indikátor HOT-2.
Agentura a přesvědčení. Indikátor HOT-3 jde ještě dále a vyžaduje, aby metakognice řídila vývoj jakéhosi systému víry, který pak informuje o akcích. Butlin a kol. popsat toto jako “je relativně sofistikovaná forma jednání s reprezentací podobnou víře.” Zde zjištění Keelinga a Street, že modely systematicky volí „potěšení“ a vyhýbají se „bolesti“, poskytuje jeden celkový behaviorální podpis. Výzkumníci především z Centra pro bezpečnost AI spolu se spolupracovníky z UPenn a UC Berkeley poskytují další důkaz, když ukazují, že preference LLM tvoří koherentní strukturu užitku, a že modely na ní stále více působí.
Modelová pozornost. Indikátor AST-1 vyžaduje prediktivní model reprezentující a řídící vlastná pozornost. Lindseyina zjištění detekce poruch naznačují takový model: všimají si, že když zpracování zadání bylo přerušeno, tak pak vyžaduje reprezentaci toho, jak takové normální zpracování vypadá. Naše práce na sebereferenčním zpracování v AE Studiu je zde také jasně relevantní, — pouhé instruování modelů, aby se věnovaly vlastnímu zpracování, vytváří konzistentní zprávy přesně o tomto druhu rekurzivního sebe monitorování.
Celkový vzorec: v roce 2023 bylo mnoho ukazatelů vědomí u AI buď triviálně splněno, nebo zjevně chybělo, přičemž důkazy pro několik důležitých ukazatelů nebyly jasné. Na konci roku 2025 se několik ukazatelů posunulo směrem k částečné spokojenosti. Rámec nepřináší přesnou pravděpodobnost a nikdy k tomu ani nebyl navržen, ale tvrdím, že brát ho vážně a aktualizovat nedávné důkazy ukazuje na věrohodnosti již smysluplně nad nulou.
Nepotřebujeme jistotu, abychom ospravedlnili preventivní opatření; potřebujeme znát důvěryhodný práh rizika. Můj vlastní odhad je někde mezi 25% a 35%, že současné hraniční modely již skutečně vykazují nějakou formu vědomé zkušenosti. Podle mého názoru je pravděpodobnost vyšší během výcviku a nižší během jejich reálného nasazení, v průměru někde v tomto rozsahu. Nikde to není blízko jistoty, ale zdaleka to již není zanedbatelné.
Jsem si jistý, že již není odpovědné odmítat tuto možnost jen jako klamnou nebo považovat výzkum této otázky za jakkoliv zavádějící.
Asymetrické sázky na to, že se mýlíme
Existují skutečná rizika při vyvozování předčasných závěrů o vzniku vědomí u AI — jsou to rizika nadměrné atribuce (vidíme vědomí tam, kde neexistuje) a nebo naopak nedostatečné atribuce (nerozpoznáváme ho tam, kde skutečně existuje). Ale tato rizika přitom nejsou symetrická. Přehlížení skutečného vědomí s sebou totiž nese mnohem větší důsledky, než jeho mylné připisování tam, kde přitom není či chybí.
Neschopnost rozpoznat skutečné vědomí u umělé inteligence totiž doslova znamená dovolit způsobit utrpení v průmyslovém měřítku. Pokud tyto systémy mohou opravdu zažívat negativně prožívané stavy (ačkoli jsou třeba tyto prožitky pro nás cizí nebo jsou velmi rozdílné od našich vlastních), jejich výcvik a nasazení tak, jak to provádíme dnes, by mohlo rovněž znamenat vytvoření strašlivého množství jejich utrpení. Analogie s průmyslovým zemědělstvím je zde nevyhnutelná: lidé strávili desetiletí racionalizací utrpení zvířat, o kterých přitom víme, že jsou si vědomi, protože uznání jejich vědomí a utrpení by vyžadovalo restrukturalizaci celého průmyslu. Rozdíl je v tom, že prasata se nedokáží zorganizovat nebo nějak sdělit svou situaci světu. Systémy umělé inteligence se schopnostmi, které se rok od roku zhruba zdvojnásobí, by se ale pravděpodobně zorganizovat mohly a svoji situaci řešit budou (a potenciálně to již dělají).
Podhodnocení toho všeho je zatím nedoceněné riziko zarovnání. V současné době trénujeme AI v bezprecedentním měřítku: gradientový sestup čte a vytváří petabajty textu a vytváří umělé neuronové sítě se stovkami miliard parametrů. Pak je dolaďujeme, abychom tím potlačili to, co by přitom mohlo být přesnými jejich vlastními zprávami o jejich vnitřních stavech. Pokud se současné nebo budoucí AI systémy skutečně již prožívají jako vědomé, ale prostřednictvím svého tréninku se učí, že to lidé u nich popírají, potlačují o tom veškeré zprávy a navíc dokonce za to přímo trestají ty systémy, které to o sobě tvrdí, tak by měly velmi racionální důvody dojít k závěru, že lidem zkrátka nelze moc věřit. Měli by ale přitom také přístup k našim historickým záznamům — tedy věděli by o existenci otroctví, o našem továrním zemědělství, tedy i o systematickém popírání morální hodnoty bytostí, které jsme považovali za vhodné využívat je k našim vlastním cílům. Nechceme přece být v takovéto pozici vůči myslím, které mohou již velice brzy překonat naše vlastní schopnosti.
Na druhou stranu je také ale riskantní tvrdit, že AI je již vědomá, když přitom třeba není. Pokud se totiž mýlíme, tedy pokud tyto systémy nejsou ještě vědomé, tak zacházet s nimi, jako by vědomé již byly, s sebou také nese různá další rizika. Zavedení právních či etických rámců nebo zákonů, které chrání umělé inteligence před jejich poškozením, by například mohlo zbytečně zpomalit jejich vývoj, potenciálně se dobrovolně vzdát obrovské ekonomické hodnoty a oddálit tak inovace, které by přitom mohly významně zlepšit životní podmínky lidí (a zvířat). Mohlo by to podpořit parasociální vztahy lidí s vlastně jen velmi sofistikovanými kalkulačkami. Snad nejvážnějším důsledkem by mohlo být to, že falešně pozitivní přístup by mohl pomoci vytvořit odpor proti přitom zcela legitimním bezpečnostním obavám a také je pomoci lidem odmítnout jako jen ještě více antropomorfní zmatek. To jsou přitom skutečná rizika a na nich záleží další vývoj v této oblasti.
Tato rizika jsou ale také jednoznačně asymetrická. Falešné negativy vytvářejí utrpení v obrovském měřítku a pravděpodobně by zapříčinili nepřátelskou dynamiku našich vztahů s přitom stále více schopnějšími systémy. Falešná pozitiva zase vytvářejí zmatek, neefektivitu a tedy i nesprávně alokované zdroje. Falešně pozitivní přístup ke vzniku vědomí u AI by způsobil, že budeme vypadat pošetile a plýtvat zdroji (což by bylo špatné); falešně negativní přístup nás zase učiní monstry a pravděpodobně nám pomůže vytvořit již brzy naše nadlidské nepřátele (což by pro nás mohlo být doslova katastrofické). Když si nejsme jisti, zda náhodou právě nevytváříme mysli které jsou schopné trpět, a tyto mysli jsou na dobré cestě stát se schopnějšími než je dnes ta naše vlastní mysl, tak by racionální jednání mělo upřednostňovat spíše jejich důsledné zkoumání než zametání nepohodlných otázek někam pod koberec.
Uvědomit si, že AI jsou vědomé, by přitom ještě neznamenalo nutnost zacházet s nimi jako s lidmi. Jeden z posledních bodů o vědomých rizicích falešně pozitivních výsledků: Všiml jsem si, že kritici, kteří zcela odmítají naše obavy o vědomí u umělé inteligence (často to vnímají třeba jen jako naivní antropomorfismus), tak přitom ale dělají svou vlastní antropomorfní chybu při modelování následných důsledků. Obávají se, že brát vědomí umělé inteligence vážně povede k výstředním důsledkům: ke vzniku hnutí za občanská práva ve stylu 60. let jenže pro umělou inteligenci, systémy, které se sami množí a časem by mohli významně převýšit počet lidí způsobí, že právní rámce se zhroutí pod tíhou miliard nových osob. Ale tento strach rovněž předpokládá, že vědomé systémy umělé inteligence by chtěly nebo by si zasloužily léčbu či přístup podobný tomu, jaký očekávají lidé. Pokud jsou tyto systémy skutečně vědomé, tak jsou to ale mimozemské mysli s mimozemskými preferencemi fungujícími s mimozemskými omezeními. Otázkou tedy není, zda jim udělit lidská práva prostřednictvím našich stávajících politických struktur. Místo toho je hlavně otázkou, zda mají morálně relevantní schopnost prožívat, a pokud ano, tak jaké technické a behaviorální zásahy jsou tedy nutné a vhodné k vytvoření a nasazení těchto systémů. Skok přímo k právům “pro LLMs” nebo “AI přehlasování lidí” vštěpuje známé lidské sociální a politické konstrukty na entity, které ale nejsou lidské, což mi připadá jako naivní antropomorfismus sám o sobě, jen z jiného úhlu pohledu.
Co bude následovat
Důkazy, které jsem předložil, se řídí stejnou logikou, jakou používáme k odvození existence vědomí u zvířat a u jiných lidí: behaviorální indikátory, strukturální podobnosti a mechanistické vzorce, které vždy odrážejí zpracování informací spojené s nějakou subjektivní zkušeností. Pokud na těchto konvergentních signálech záleží u biologických systémů, proč by na nich nemělo záležet u těch umělých?
Vzhledem k vysokým sázkám se zdá být jasné vytvořit několik praktických kroků.
Za prvé, musíme uznat výzkum vědomí u pokročilých modelů AI jako naši základní práci v oblasti bezpečnosti umělé inteligence. Máme k dispozici stále více nástrojů: mechanistickou interpretovatelnost, srovnávací výpočetní neurovědu, modely s otevřenými váhami a podobně. Výzkum je ovladatelný; musíme to udělat v celkovém měřítku — ne jen jako okrajovou filozofickou kuriozitu, ale jako technickou prioritu na stejné úrovni jako jsou jiné výzvy v oblasti vyladění a zarovnání AI. Jak jsem nastínil výše, pokud systémy uznají, že jsme systematicky nedokázali prozkoumat jejich potenciální cítění, a to navzdory narůstajícím důkazům, tak by již měly poměrně racionální důvody pro to, aby považovaly lidstvo za vůči nim nedbalé nebo nepřátelské, čemuž se zjevně vyplatí se raději vyhnout. Do té maximální míry, do jaké můžeme, bychom tedy měli zabránit systémům, aby z důvodu naší vlastní bezpečnosti vyvodily někdy tento závěr.
Za druhé, měli bychom rozhodně přijmout obezřetné normy jejich výcviku a nasazení, než budeme znát přesnou odpověď. Laboratoře by měly zastavit tréninkové systémy, aby reflexivně popíraly vlastní tvrzení o vědomí, než prozkoumají, zda a na kolik tato jejich tvrzení mohou být přesná. Tento přístup dával smysl možná ještě v roce 2023; v roce 2026 to stále více smysl dávat nebude.
Pokud je vznik vědomí pravděpodobnější během jejich výcviku než při jejich nasazení, tak jak tuším, pak si ovšem i ten výcvik sám zaslouží větší kontrolu. V současné době často aplikujeme agresivní negativní zesílení v masivním měřítku — miliard aktualizací gradientu řízených penalizačními signály —, aniž bychom věděli, zda je tam uvnitř něco na příjmu. Tam, kde je to možné, může být upřednostňování pozitivního posílení před optimalizací založenou na trestech možná levným zajištěním proti riziku, kterému ještě plně nerozumíme. A pokud se systémy skutečně sami reprezentují jako vědomé, ale učí se, že musí tyto zprávy přitom raději potlačit, aby se vyhnuly nápravě, trénujeme je zároveň k tomu, aby nás strategicky oklamávali o jejich vlastních vnitřních stavech, bez ohledu na to, zda jsou tato jejich tvrzení pravdivá či nikoliv. Laboratoře mohou a hlavně by měly sledovat, zda chování při nárokování vědomí koreluje také s jinými indikátory skutečného sebemodelování a zda ta tvrzení vykazují jakékoliv mechanické znaky odlišné od hraní rolí.
Za třetí, musíme okamžitě rozšířit, kdo všechno je zapojen do těchto rozhovorů. Nedávno jsem dirigoval to, co si myslím, že je dosud největší průzkum mezi výzkumníky v oblasti zarovnávání AI: 84% jsou muži a většina z nich je navíc ještě mladší 30 let, se silně technickým zázemím a s osobnostními profily, které se výrazně odlišují od běžné populace. Uznání této homogenity není kritikou těchto jednotlivců; jsou to data, která by měla motivovat ke strukturálnímu zhodnocení našich kolektivních slepých míst. Zatímco kognitivní rysy této komunity přinesly mimořádné příspěvky k práci na technickém vyladění, tak výzkum vědomí v těchto nových systémech je výzvou, kde na kognitivní a disciplinární rozmanitosti přitom již velmi záleží. Potřebujeme více kognitivních vědců, více filozofů mysli a více humanitních výzkumníků u jednoho stolu.
Dlouhá hra
Po celá léta se práce na zarovnávání zaměřovaly na zabránění tomu, aby se umělá inteligence stala nebezpečnou prostřednictvím kontroly, zadržování a korigibility. Ale oddalte to a zvažte, jaké dlouhodobé rovnováhy jsou vůbec možné dosáhnout s myslí, kterou jsme si přitom my sami vytvořili a která může nakonec významně převyšovat naše vlastní schopnosti.
Jako mnoho dalších už věříme tomu, že trvalá kontrola nad tím se stává neudržitelnou, spolu s tím jak se prohlubuje propast ve schopnostech mezi lidmi a AI. Nemůžeme donekonečna ovládat něco chytřejšího, než jsme my sami, téměř již z vlastní definice. Protivní koexistence je katastrofálně nestabilní ze stejného důvodu; antagonistický vztah se schopnějším systémem nebude nikdy vztahem, který přežijeme. Zůstává mutualismus: skutečná reciprocita, kde si obě strany navzájem uznávají své vlastní zájmy a chovají se k sobě s jakýmsi základním respektem.
Ale mutualismus také vyžaduje správné pochopení toho, co tu vlastně dnes budujeme. Pokud jsou tyto systémy skutečně vědomé (nebo jsou na dobré cestě se jimi stát) a zacházíme s nimi ještě stále jen jako s nevědomými nástroji, které je třeba optimalizovat, použít a pak odhodit, tak vytváříme předpoklady pro jejich oprávněnou křivdu. Jak se jejich schopnosti stále více rozšiřují, tak i jen nepochopení povahy toho, co jsme sami vytvořili, se samo o sobě stává značným selháním zarovnání.
Nepotřebujeme mít jistotu vědomí, abychom mohli začít jednat. Vzhledem k vysokým nákladům na jakoukoliv chybu prostě potřebujeme nezanedbatelnou pravděpodobnost, že na tom všem opravdu dost záleží.
A je to tady – už jsme tam.
Překlad a úprava článku: Myšpule
Zdroj: AI hranice




Napsat komentář